
Transformer Architecture
This project implements a Transformer block from scratch, using PyTorch for tensor operations and certain pre-built layers. The block consists of the following components:
Diagram
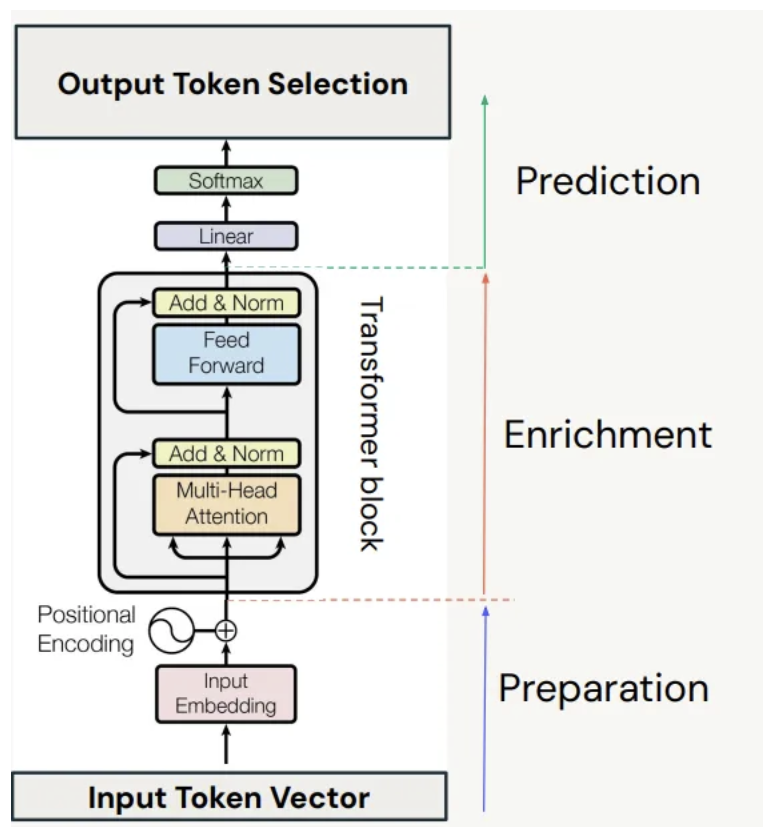
- Layer Normalization: A from-scratch implementation of
LayerNorm. It usesnn.Parameterfor trainable scale and shift parameters. - Masked Multi-Head Attention: The
MultiHeadAttentionlogic is implemented from scratch. It utilizes PyTorch’snn.Linearfor the weight matrices andnn.Dropout. - Dropout: Applied via PyTorch’s
nn.Dropoutfor regularization within the attention mechanism and on the residual connections. - Shortcut Connections (Residual Connections): Implemented by adding the input of a sublayer to its output.
- Feed Forward Network: A
FeedForwardnetwork that uses PyTorch’snn.Linearlayers and a custom-implementedGELUactivation function.
Implementation Details
- The configuration for the Transformer block is defined in the
GPT_CONFIG_124Mdictionary. This includes parameters such as embedding dimension, number of attention heads, and dropout rate. - The
TransformerBlockclass combines all the components into a single block.
Usage
An example implementation is provided in the notebook to demonstrate how to use the TransformerBlock.
# example implementation
torch.manual_seed(123)
x = torch.rand(2, 4, 768)
block = TransformerBlock(GPT_CONFIG_124M)
output = block(x)
print("Input Shape:", x.shape)
print("Output shape:", output.shape)
Written on July 11, 2025